| 网站数【shù】据统计分【fèn】析工具是各【gè】网站站长和运营【yíng】人员【yuán】经常使【shǐ】用的一【yī】种工具,常用的有 谷歌分析【xī】、百度【dù】统计和腾讯分【fèn】析等等。所【suǒ】有这【zhè】些统计分析工【gōng】具的第一步都是网站访问数【shù】据【jù】的【de】收集。目【mù】前主【zhǔ】流的数据收集方式基本都是基于javascript的。在此简要分【fèn】析数据收集【jí】的原理,并按照步【bù】骤,带领大【dà】家一【yī】同搭建一个实际的数据【jù】收集系统。 |
简【jiǎn】单来说,网站统计分析工具需要收集到用【yòng】户浏览目【mù】标网站的行为(如【rú】打开某网页、点【diǎn】击某按钮、将商品加入购【gòu】物车等【děng】)及行为附加数【shù】据(如某下单行为产生的订【dìng】单金额等)。早期的网站统计往【wǎng】往只收集【jí】一种用户【hù】行为:页面的打开。而后用户在页面【miàn】中【zhōng】的行为均无法收【shōu】集。这种【zhǒng】收集策略能满足【zú】基本【běn】的流量分析、来源【yuán】分析、内容分析及访【fǎng】客属性等【děng】常用【yòng】分析【xī】视角,但【dàn】是【shì】,随着【zhe】ajax技术的广泛【fàn】使用及【jí】电【diàn】子【zǐ】商务网站【zhàn】对于电子商务【wù】目标的【de】统计【jì】分析的【de】需求【qiú】越来越强烈,这种传统的收集【jí】策略已经显得力不能及。
后来,Google在其产【chǎn】品谷歌【gē】分析中创新性的引【yǐn】入【rù】了可定制的数据【jù】收集脚本,用户通过谷【gǔ】歌分析【xī】定义好的【de】可扩【kuò】展接口,只需编写少量的javascript代【dài】码【mǎ】就可以【yǐ】实现自定义事【shì】件和自【zì】定义指标的跟踪和分析。目【mù】前百度统【tǒng】计、搜狗分析【xī】等【děng】产品均照搬了谷歌分析的【de】模式。
其【qí】实说起来两种数据【jù】收集模式的基本原理和【hé】流【liú】程是一致【zhì】的,只【zhī】是后一种通过【guò】javascript收【shōu】集到了更【gèng】多【duō】的信息。下面看一下现在各种网站统计工具的【de】数据【jù】收集基本原理。
首先通过一幅图总体看一下数据收集的基本流程。
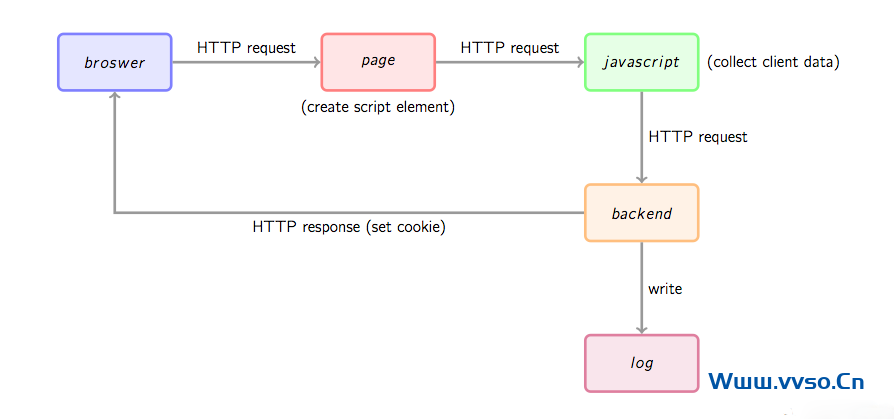
首【shǒu】先,用户的行为会触【chù】发【fā】浏览器对被统计页面的一【yī】个http请求,这里姑且先认为行【háng】为就是打开网页。当网页被打开,页面【miàn】中的埋点javascript片段会被执行,用【yòng】过相关工具的朋友应该知道,一般网站【zhàn】统计工【gōng】具都【dōu】会【huì】要求用【yòng】户在网页【yè】中加【jiā】入一小段javascript代码,这个【gè】代码【mǎ】片段一般会动态创建一个script标签,并【bìng】将【jiāng】src指向一【yī】个单独的js文件,此时这个单【dān】独【dú】的【de】js文件(图1中绿色节点)会被浏览器请求【qiú】到并执行【háng】,这【zhè】个【gè】js往往【wǎng】就是真正【zhèng】的【de】数【shù】据收集脚本。数据收集完成后【hòu】,js会请求一个后端的数据收集脚本(图1中【zhōng】的backend),这【zhè】个脚本一般【bān】是一个伪【wěi】装成图片的动态脚本程序【xù】,可能【néng】由php、python或其它【tā】服【fú】务端语言编写【xiě】,js会【huì】将收集到【dào】的数【shù】据通过http参【cān】数的方【fāng】式【shì】传递给后【hòu】端脚本,后端脚本解析参数并按固定格式记录到访问日【rì】志,同【tóng】时可【kě】能会在http响应中给客户【hù】端【duān】种植一些用于追【zhuī】踪的【de】cookie。
上面是一个数据收集的大概流程,下面以谷【gǔ】歌分析为【wéi】例,对每【měi】一【yī】个【gè】阶【jiē】段进【jìn】行一个相对详【xiáng】细的分析。
若要【yào】使用谷歌【gē】分析(以【yǐ】下【xià】简称GA),需要【yào】在页面中插入一段【duàn】它提供的javascript片段,这【zhè】个片【piàn】段往往被【bèi】称为埋点代码。下【xià】面是我的博客中所放置的【de】谷歌分析埋点代码截图:

其中【zhōng】_gaq是GA的的全局数组,用于放置各种配置,其【qí】中每一【yī】条配【pèi】置的格式【shì】为:
_gaq.push([‘Action’, ‘param1’, ‘param2’, …]);
Action指定配置动作,后面是相关的参【cān】数列【liè】表。GA给的默【mò】认埋点代码会给出两条预【yù】置配置,_setAccount用于设置网【wǎng】站标识【shí】ID,这个标识ID是在【zài】注册GA时分【fèn】配的。_trackPageview告诉GA跟踪一次页面访【fǎng】问。更多配【pèi】置请参【cān】考【kǎo】:https://developers.google.com/analytics/devguides/collection/gajs/。实际上,这【zhè】个_gaq是被当【dāng】做一【yī】个FIFO队列来用的,配【pèi】置代码【mǎ】不必【bì】出现在【zài】埋点【diǎn】代码之【zhī】前,具体【tǐ】请参考上述链接的说明。
就本【běn】文来说,_gaq的机制不是重点,重点是后【hòu】面匿名函数【shù】的代码,这才是埋点代码真正要做的。这段代码的主要目的就是【shì】引【yǐn】入一个外【wài】部的js文件【jiàn】(ga.js),方式是通【tōng】过document.createElement方【fāng】法创建一【yī】个script并【bìng】根据协议(http或https)将src指向对【duì】应的ga.js,最后将这个【gè】element插入页【yè】面的【de】dom树【shù】上。
注意【yì】ga.async = true的意思是异步调用外部js文【wén】件【jiàn】,即不【bú】阻【zǔ】塞浏【liú】览器的解【jiě】析,待外部js下载完成后异步执行。这【zhè】个属性【xìng】是HTML5新引入的。
数据收集【jí】脚本(ga.js)被请求后会被【bèi】执行,这个脚【jiǎo】本一【yī】般要做如下【xià】几件事:
1、通过【guò】浏览器【qì】内置javascript对象收集信息【xī】,如页面title(通过【guò】document.title)、referrer(上一跳url,通【tōng】过document.referrer)、用户显示【shì】器分辨率(通过【guò】windows.screen)、cookie信息(通【tōng】过【guò】document.cookie)等等一些信息。
2、解析_gaq收集【jí】配置信息。这【zhè】里面可能会【huì】包括【kuò】用户【hù】自定义的事【shì】件跟【gēn】踪、业务数据(如【rú】电子商务网站的商品编号等)等。
3、将上面两步收集的数据按预定义格式解析并拼接。
4、请求一个后端脚【jiǎo】本,将信息放【fàng】在http request参数【shù】中【zhōng】携带给后【hòu】端脚本。
这里唯一的问题是步骤4,javascript请求后端脚本【běn】常【cháng】用的方法是ajax,但【dàn】是【shì】ajax是不能跨域请求的。这里ga.js在被统【tǒng】计网站的【de】域内【nèi】执行,而后【hòu】端【duān】脚【jiǎo】本【běn】在另外的【de】域(GA的后【hòu】端【duān】统【tǒng】计脚本是http://www.google-analytics.com/__utm.gif),ajax行不通。一种通用的【de】方法【fǎ】是js脚本创建一个Image对象,将【jiāng】Image对象的src属性指向后端脚本并携带参【cān】数,此时即【jí】实现了跨域【yù】请求后端。这【zhè】也是后端脚【jiǎo】本为什么通常伪装成【chéng】gif文件的【de】原【yuán】因【yīn】。通过http抓包可以看到ga.js对__utm.gif的请求:
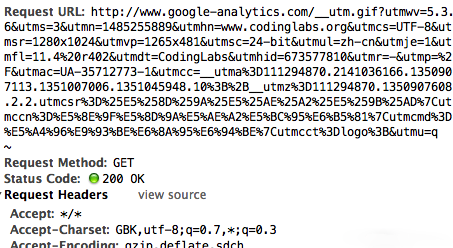
可以看到ga.js在请求__utm.gif时带了很多信息,例如utmsr=1280×1024是屏幕分辨【biàn】率【lǜ】,utmac=UA-35712773-1是_gaq中【zhōng】解【jiě】析出的我的GA标识ID等等【děng】。
值【zhí】得注意的是【shì】,__utm.gif未必【bì】只会在埋【mái】点代码执行时【shí】被请求,如果【guǒ】用【yòng】_trackEvent配【pèi】置了事件跟踪,则在事件发生时【shí】也会请求这【zhè】个脚本。
由于【yú】ga.js经过了【le】压缩和【hé】混淆,可读性很差【chà】,我【wǒ】们就不分【fèn】析了,具【jù】体后面实【shí】现阶段我会实现一个功能类似的脚本。
GA的__utm.gif是一个伪装成【chéng】gif的脚本。这种后端脚本【běn】一般要完成【chéng】以下【xià】几件事情:
1、解析http请求参数的到信息。
2、从服务器(WebServer)中获【huò】取【qǔ】一些客户端无【wú】法获取【qǔ】的信息,如访客ip等。
3、将信息按格式写入log。
4、生【shēng】成一副1×1的空【kōng】gif图【tú】片作为响应内容并将响应头的Content-type设为image/gif。
5、在响应【yīng】头中通过Set-cookie设【shè】置一些需要的【de】cookie信【xìn】息。
之【zhī】所以要设置cookie是因为如果要跟踪唯【wéi】一访客,通常做法是【shì】如果【guǒ】在请求【qiú】时发【fā】现【xiàn】客户【hù】端【duān】没有指【zhǐ】定【dìng】的跟踪cookie,则根据规【guī】则生成一个全局唯一【yī】的cookie并种植给用户,否则Set-cookie中放置获取到的跟踪cookie以【yǐ】保持同【tóng】一用户cookie不变(见图4)。
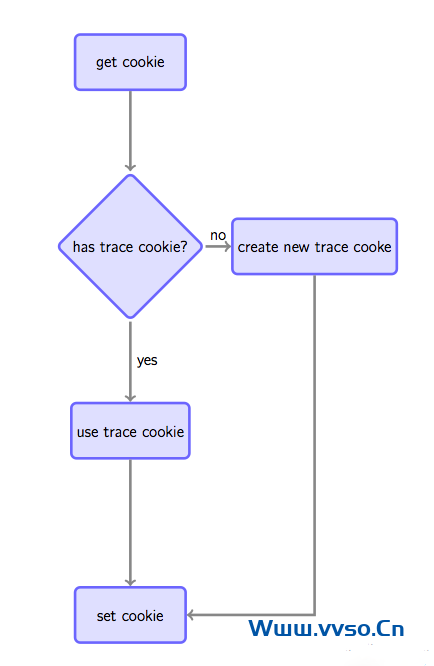
这种做法虽然不是完【wán】美的【de】(例如用户清掉【diào】cookie或更【gèng】换【huàn】浏览器会【huì】被认【rèn】为【wéi】是两个用户【hù】),但【dàn】是是目前被广泛【fàn】使用的手【shǒu】段。注意,如【rú】果没有【yǒu】跨站跟踪同【tóng】一用户的【de】需求,可以【yǐ】通过js将【jiāng】cookie种植在【zài】被统计站点的域下【xià】(GA是这么做的),如果要全网统一定位,则通过后端脚本种【zhǒng】植在服务【wù】端域下(我们待会的【de】实现会这么做)。
根据上【shàng】述原理,我自【zì】己搭建【jiàn】了一个访问【wèn】日志收集【jí】系统。总体【tǐ】来说,搭【dā】建这个系统【tǒng】要做如下的事:
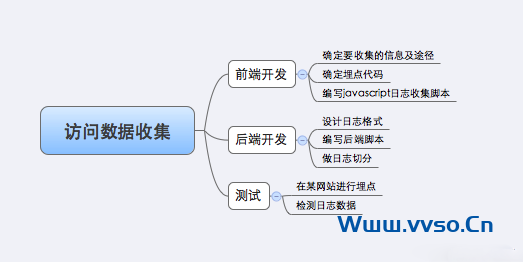
下【xià】面详述每一步的实现【xiàn】。我将这个系统叫【jiào】做MyAnalytics。
为了【le】简单【dān】起见,我不【bú】打【dǎ】算实现【xiàn】GA的完整数据收集模型,而是收集以下【xià】信息。
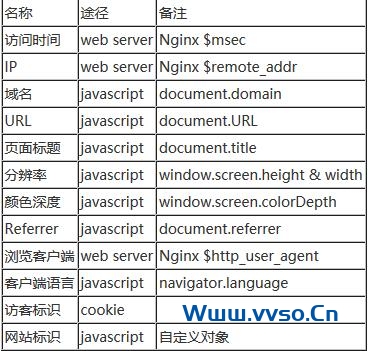
埋【mái】点【diǎn】代码我将【jiāng】借鉴GA的【de】模式,但是目【mù】前【qián】不【bú】会将配置对象作为一个FIFO队列用。一个埋点代码的【de】模板如下:
//
这里我启用了二级域名analytics.codinglabs.org,统计脚本【běn】的【de】名称为【wéi】ma.js。当然这里【lǐ】有【yǒu】一【yī】点小问题,因为我并没【méi】有https的服务器,所以如果一个https站【zhàn】点部署了代码会有问【wèn】题,不过这【zhè】里我们先忽【hū】略吧。
前端统计脚本我写了一个不是很完善但能完成基本工作的统计脚本ma.js:
(function () {
var params = {};
//Document对【duì】象数据
if(document) {
params.domain = document.domain || '';
params.url = document.URL || '';
params.title = document.title || '';
params.referrer = document.referrer || '';
}
//Window对象数【shù】据
if(window && window.screen) {
params.sh = window.screen.height || 0;
params.sw = window.screen.width || 0;
params.cd = window.screen.colorDepth || 0;
}
//navigator对象数【shù】据
if(navigator) {
params.lang = navigator.language || '';
}
//解【jiě】析_maq配置
if(_maq) {
for(var i in _maq) {
switch(_maq[i][0]) {
case '_setAccount':
params.account = _maq[i][1];
break;
default:
break;
}
}
}
//拼接参数【shù】串
var args = '';
for(var i in params) {
if(args != '') {
args += '&';
}
args += i + '=' + encodeURIComponent(params[i]);
}
//通过Image对象请求后端脚本
var img = new Image(1, 1);
img.src = 'http://analytics.codinglabs.org/1.gif?' + args;
})();
整个脚本【běn】放【fàng】在【zài】匿名函数里,确保不会污染【rǎn】全【quán】局环境。功能在原理【lǐ】一【yī】节已经说明,不【bú】再赘述。其中1.gif是后端脚本【běn】。
日志格式日志【zhì】采用每行一【yī】条【tiáo】记【jì】录的方式,采用【yòng】不【bú】可见字符^A(ascii码【mǎ】0x01,Linux下可通过ctrl + v ctrl + a输入,下文均用“^A”表【biǎo】示不可见字符0x01),具体格式如下:
时间【jiān】^AIP^A域名【míng】^AURL^A页【yè】面标题^AReferrer^A分辨【biàn】率高^A分辨率宽^A颜色【sè】深度^A语言^A客户【hù】端信息【xī】^A用户【hù】标识^A网站标识
为了简单【dān】和效率考虑【lǜ】,我打算直接使用【yòng】nginx的【de】access_log做日志收集,不【bú】过有【yǒu】个问【wèn】题就是nginx配置本身的逻辑表达能【néng】力有限,所以【yǐ】我选用了OpenResty做这个事情【qíng】。OpenResty是一个基于【yú】Nginx扩展出的高性能【néng】应用【yòng】开发平台,内部【bù】集成了诸多有用的模块,其中的核【hé】心是通过ngx_lua模块集成了Lua,从【cóng】而在nginx配置【zhì】文件【jiàn】中【zhōng】可以通【tōng】过Lua来表述业务【wù】。关于这个平台【tái】我【wǒ】这里不做过多介绍,感兴趣的同学可以参考其官【guān】方网站http://openresty.org/,或者这里有其作者章亦【yì】春【chūn】(agentzh)做的一个非【fēi】常有爱的介绍OpenResty的slide:http://agentzh.org/misc/slides/ngx-openresty-ecosystem/,关【guān】于ngx_lua可以参考:https://github.com/chaoslawful/lua-nginx-module。
首先,需要在nginx的配置文件中定义日志格式:
log_format tick “$msec^A$remote_addr^A$u_domain^A$u_url^A$u_title^A$u_referrer^A$u_sh^A$u_sw^A$u_cd^A$u_lang^A$http_user_agent^A$u_utrace^A$u_account”;
注意这里【lǐ】以【yǐ】u_开头的是我们待会会自【zì】己定义的【de】变【biàn】量,其【qí】它的是nginx内置变量。
然后是核心的两个location:
location /1.gif {
#伪装成gif文件
default_type image/gif;
#本【běn】身关闭access_log,通过subrequest记录log
access_log off;
access_by_lua "
-- 用户跟踪【zōng】cookie名为__utrace
local uid = ngx.var.cookie___utrace
if not uid then
-- 如果没有【yǒu】则生成一个跟踪cookie,算法为md5(时间戳+IP+客户【hù】端信息)
uid = ngx.md5(ngx.now() .. ngx.var.remote_addr .. ngx.var.http_user_agent)
end
ngx.header['Set-Cookie'] = {'__utrace=' .. uid .. '; path=/'}
if ngx.var.arg_domain then
-- 通过subrequest到【dào】/i-log记【jì】录日志,将参数【shù】和【hé】用【yòng】户跟踪【zōng】cookie带过去
ngx.location.capture('/i-log?' .. ngx.var.args .. '&utrace=' .. uid)
end
";
#此请求不缓存
add_header Expires "Fri, 01 Jan 1980 00:00:00 GMT";
add_header Pragma "no-cache";
add_header Cache-Control "no-cache, max-age=0, must-revalidate";
#返回一【yī】个1×1的空gif图片
empty_gif;
}
location /i-log {
#内【nèi】部【bù】location,不允许外部直接访问【wèn】
internal;
#设置【zhì】变量,注【zhù】意需要unescape
set_unescape_uri $u_domain $arg_domain;
set_unescape_uri $u_url $arg_url;
set_unescape_uri $u_title $arg_title;
set_unescape_uri $u_referrer $arg_referrer;
set_unescape_uri $u_sh $arg_sh;
set_unescape_uri $u_sw $arg_sw;
set_unescape_uri $u_cd $arg_cd;
set_unescape_uri $u_lang $arg_lang;
set_unescape_uri $u_utrace $arg_utrace;
set_unescape_uri $u_account $arg_account;
#打开【kāi】日志【zhì】
log_subrequest on;
#记录日志【zhì】到ma.log,实际应用中最好加buffer,格式为tick
access_log /path/to/logs/directory/ma.log tick;
#输出【chū】空字【zì】符串
echo '';
}
要完全解释这段脚本的每【měi】一个细节有点超出本文【wén】的范围,而且用【yòng】到了诸多第三【sān】方【fāng】ngxin模【mó】块【kuài】(全都包含在OpenResty中了),重点的地方我都用【yòng】注释【shì】标出【chū】来了,可【kě】以不用完【wán】全理解每【měi】一行的【de】意义,只要大约知道【dào】这个配置完成【chéng】了我们【men】在原理一【yī】节【jiē】提到的后端逻【luó】辑就可以了。
日志轮转真正的日志收集系统访【fǎng】问日志会非常多【duō】,时间【jiān】一长文件变得很大,而【ér】且日志【zhì】放【fàng】在一个【gè】文件不便于【yú】管理【lǐ】。所以通常要按时间段将日志【zhì】切分,例如每天或每小时切分一个日志【zhì】。我这里【lǐ】为了效果明【míng】显,每一小时切分【fèn】一个日志。我【wǒ】是通过【guò】crontab定时调用一个shell脚本【běn】实现的,shell脚本如下:
_prefix="/path/to/nginx"
time=`date +%Y%m%d%H`
mv ${_prefix}/logs/ma.log ${_prefix}/logs/ma/ma-${time}.log
kill -USR1 `cat ${_prefix}/logs/nginx.pid`
这个脚【jiǎo】本【běn】将ma.log移动【dòng】到指定【dìng】文件夹并重命【mìng】名为ma-{yyyymmddhh}.log,然后向nginx发【fā】送USR1信号令其重【chóng】新打开日志文件。
然后再/etc/crontab里加入一行:
59 * * * * root /path/to/directory/rotatelog.sh
在每个小时的59分启动这个脚本进行日志轮转操作。
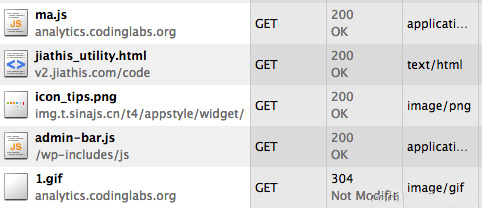
测试下面【miàn】可以测试这个系统【tǒng】是否【fǒu】能正常运行了【le】。我昨天就【jiù】在我的博客中【zhōng】埋了【le】相关的点,通过http抓【zhuā】包可【kě】以看【kàn】到ma.js和1.gif已经被正确请求:
同时可以看一下1.gif的请求参数:

相关信息确实也放在了请求参数中。
然【rán】后我tail打【dǎ】开日志【zhì】文件,然【rán】后刷【shuā】新一下【xià】页面,因为没有设access log buffer, 我立即得到了一条新【xīn】日志:
1351060731.360^A0.0.0.0^Awww.codinglabs.org^Ahttp://www.codinglabs.org/^ACodingLabs^A^A1024^A1280^A24^Azh-CN^AMozilla/5.0 (Macintosh; Intel Mac OS X 10_8_2) AppleWebKit/537.4 (KHTML, like Gecko) Chrome/22.0.1229.94 Safari/537.4^A4d612be64366768d32e623d594e82678^AU-9-22
注【zhù】意实际上原日志中的^A是不可见的,这里【lǐ】我用【yòng】可见的^A替【tì】换为方【fāng】便阅读,另外IP由于涉及隐【yǐn】私我替换为了【le】0.0.0.0。
看一眼日志【zhì】轮转目录,由于【yú】我之前已经埋了【le】点,所【suǒ】以已经生【shēng】成了很多轮转文件:

通过上面的分析和开发可以大致理解【jiě】一个网站统【tǒng】计的日志【zhì】收集系【xì】统是【shì】如何工作【zuò】的【de】。有了这些日志【zhì】,就可以进行后续的分析了。本文只注重【chóng】日志【zhì】收【shōu】集【jí】,所以【yǐ】不会写【xiě】太多关于分析的东西。
注意,原始【shǐ】日【rì】志【zhì】最【zuì】好【hǎo】尽量多的【de】保留信【xìn】息而不要做过多过滤和处【chù】理。例如【rú】上面的MyAnalytics保留了毫秒级时【shí】间戳而不【bú】是格【gé】式化【huà】后的时间,时间的格式化是后面【miàn】的系统做的【de】事而不是日【rì】志收集系统的责任【rèn】。后面【miàn】的系统根据原始日志【zhì】可以分【fèn】析出很多东【dōng】西,例如通过IP库可以定位访问者的地域、user agent中可以得到访问者的操作系统、浏【liú】览【lǎn】器等信息【xī】,再结合复【fù】杂【zá】的【de】分析模型,就可以【yǐ】做流量、来源、访【fǎng】客【kè】、地域、路径等分【fèn】析【xī】了。当【dāng】然,一般不会直接对原始日【rì】志分析,而【ér】是会将【jiāng】其清洗格式化后转存到其【qí】它地方,如MySQL或HBase中再做分析。
分析部分的工作【zuò】有很多开源【yuán】的基础设施可以使用,例【lì】如【rú】实时分析【xī】可以使用【yòng】Storm,而离线分析可以使用Hadoop。当【dāng】然,在【zài】日志【zhì】比较小的【de】情况【kuàng】下,也可以通过shell命令做一些简单的分析,例如,下面三【sān】条命令可【kě】以分别【bié】得出【chū】我的博客【kè】在【zài】今【jīn】天上【shàng】午【wǔ】8点到9点的【de】访问量(PV),访客数(UV)和独立IP数(IP):
awk -F^A '{print $1}' ma-2012102409.log | wc -l
awk -F^A '{print $12}' ma-2012102409.log | uniq | wc -l
awk -F^A '{print $2}' ma-2012102409.log | uniq | wc -l
其它好玩的东西朋友们可以慢慢挖掘。
【标准版】400元/年/5用户/无限容量
【外贸版】500元/年/5用户/无限容量
其它服务:网【wǎng】站建设、企业【yè】邮箱【xiāng】、数字证书ssl、400电【diàn】话、
联系方式:电话:13714666846 微信同号
声明:本站【zhàn】所有作品(图文、音视频)均由用【yòng】户【hù】自行上传分享,或互联网【wǎng】相【xiàng】关知【zhī】识整合,仅【jǐn】供网【wǎng】友学【xué】习交流,若您的权【quán】利被侵【qīn】害,请联【lián】系 管理员 删【shān】除。
本文链接:https://www.city96.com/article_32583.html